非关系数据库DynamoDB
DynamoDB是一种非关系数据库(NoSQL),可在任何规模提供可靠的性能。DynamoDB能在任何规模下实现不到10毫秒级的一致相应,并且它的存储空间无限。
DynamoDB的特点:
- 使用SSD存储
- 数据分散在3个不同地理位置的数据中心(并不是3个可用区)
- 最终一致性读取(Eventual Consistent Reads)
- 默认的设置,即如果写入数据到DynamoDB之后马上读取该数据,可能会读取到旧的信息
- DynamoDB需要时间(一秒内)把写入的数据同步到3个不同地理位置的数据中心
- 强一致性读取(Strongly Consistent Reads)
- 在写入数据到DynamoDB之后马上读取该数据,会等所有写入操作以及数据同步全部完成后再回馈结果
- 即强一致性读取一定会读到最新的数据结果
- 如果我们需要增加DynamoDB的规格,我们可以直接在AWS管理控制台上进行更改,并且不会有任何系统downtime
- 除非您指定其他读取方式,否则 DynamoDB 将使用最终一致性读取。读取操作 (例如 GetItem,Query 和 Scan) 提供了一个 ConsistentRead 参数。如果您将此参数设置为 true,DynamoDB 将在操作过程中使用强一致性读取。
下面我们会创建一个新的DynamoDB,以及创建一些基础的表。
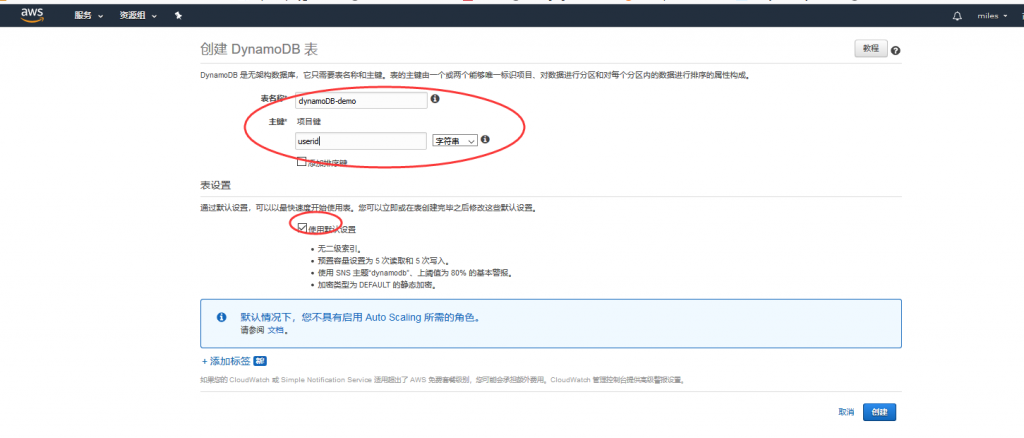
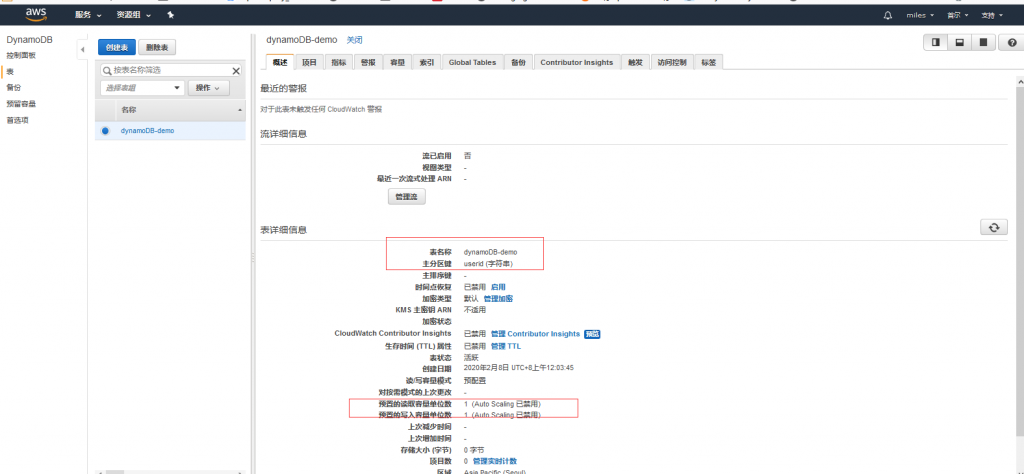
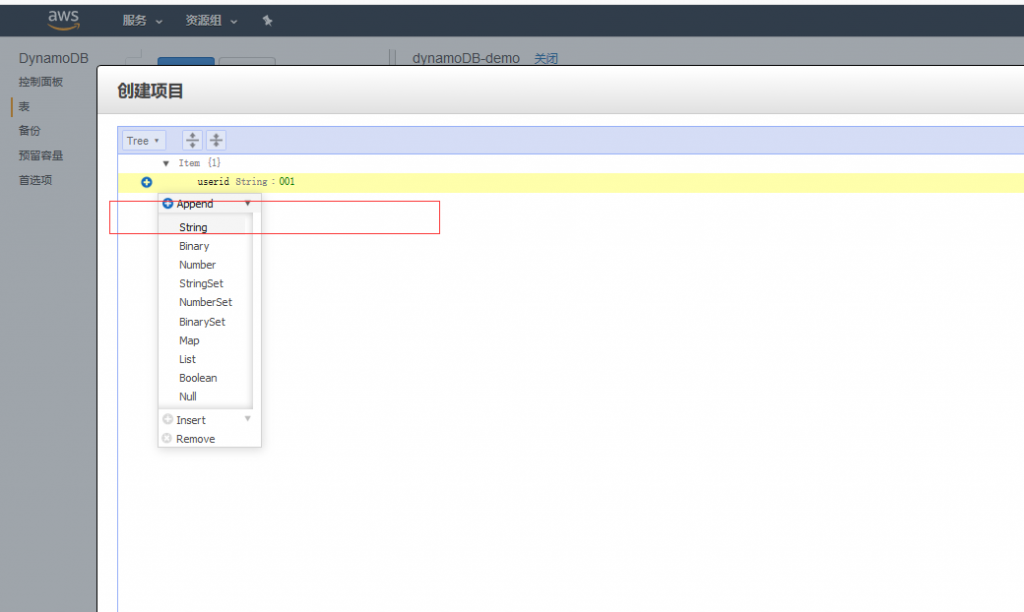
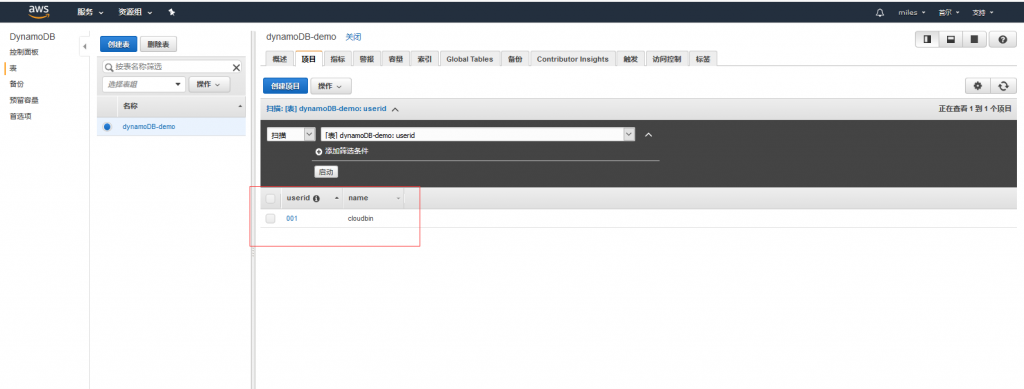
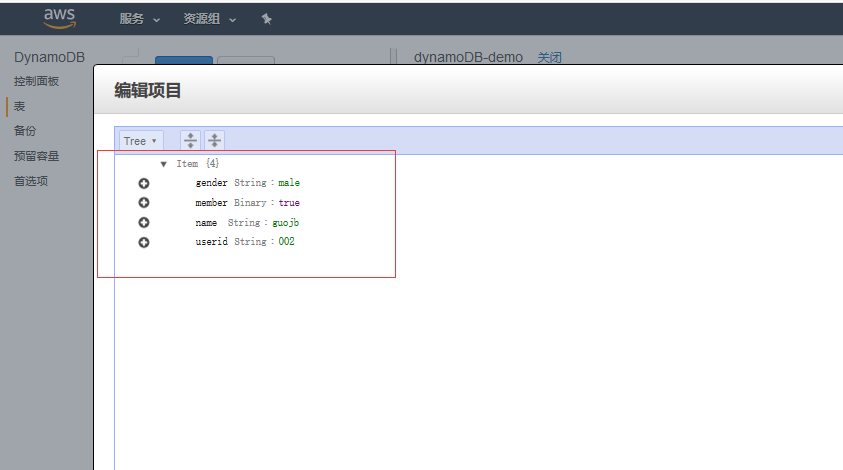
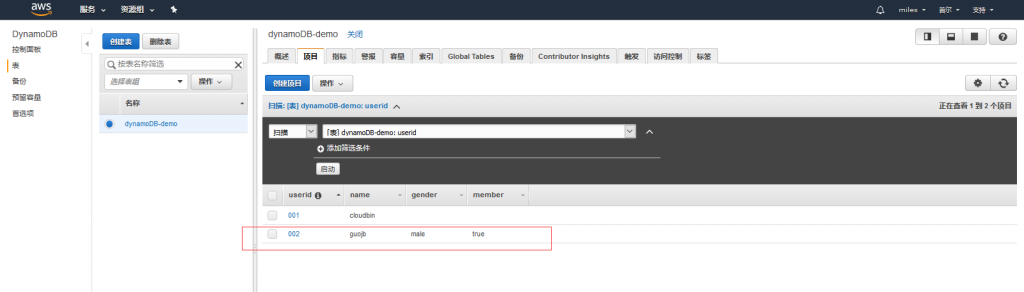
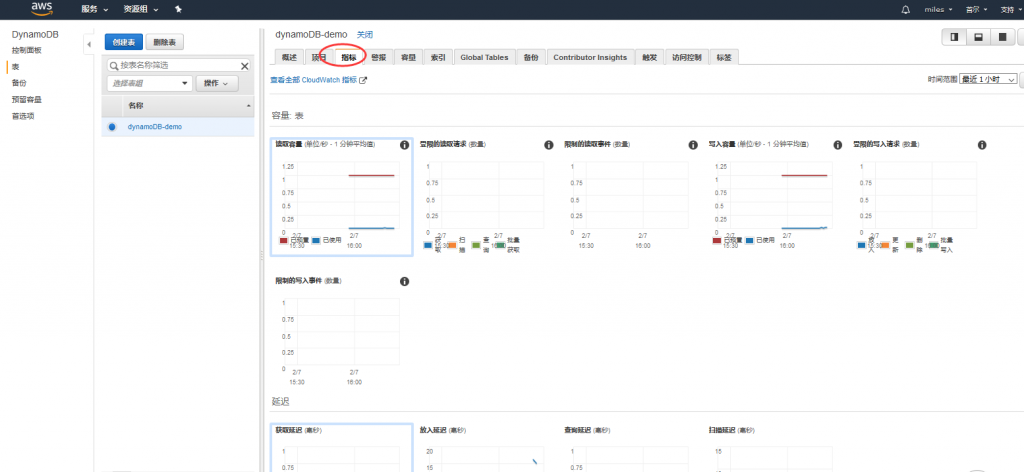
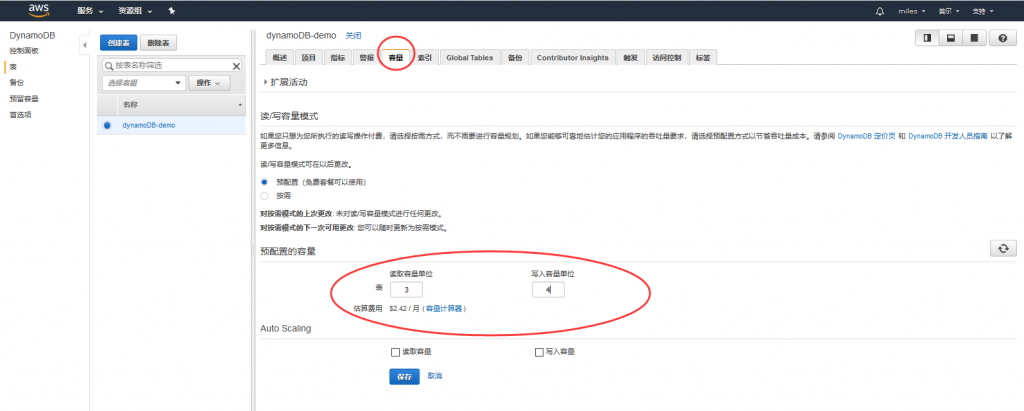
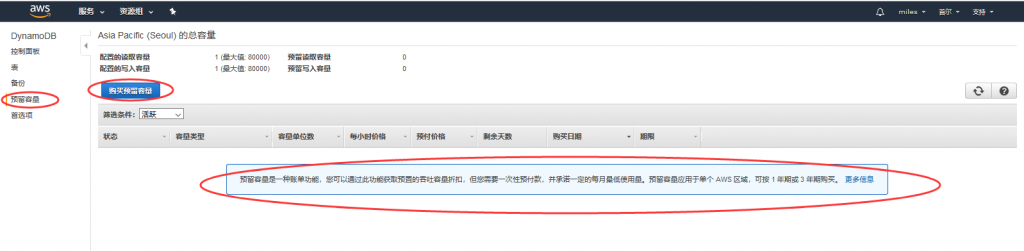
容量单位 读、写的容量都从5该成1 这个容量指的是什么?
是一种比较新颖的计算方式:一个读取请求单位表示对大小最多为 4 KB 的项目执行一次强一致性读取请求,或执行两次最终一致性读取请求。一个写入请求单位表示对大小最多为 1 KB 的项目执行一次写入。具体可以参照下这里。
Redshift简介
Amazon Redshift是一个快速、功能强大、完全托管的PB级别数据仓库服务。用户可以在刚开始使用几百GB的数据,然后在后期扩容到PB级别的数据容量。

如之前的课程中所说,Redshift是一种联机分析处理OLAP(Online Analytics Processing)的类型,支持复杂的分析操作,侧重决策支持,并且能提供直观易懂的查询结果。
再举个之前提到的例子:
如果一个传统的电商发展到一定的规模,运营者/管理层需要做更加精细的用户群体分析,比如“20-30岁的男性在过去一年内的购买行为与电商促销活动之间的关系”,那么就要用到数据仓库了。
数据仓库在数据库层面和基础架构层面都与联机事务处理OLTP(Online Transaction Processing)不太一样。
Redshift的一些特点:
- 单节点(160Gb)部署模式
- 多节点部署模式
- 领导节点:管理连接和接收请求
- 计算节点:存储数据,执行请求和计算任务,最多可以有128个计算节点
- Columnar Data Storage
- Advanced Compression
- Massively Parallel Processing (MPP)
- 目前Redshift只能部署在一个可用区内,不能跨可用区或者用类似RDS的高可用配置
- Redshift是用来产生报告和做商业分析的,并不需要像生产环境一样对可用性有高保证
- 我们可以对Redshift做快照,并且在需要的时候恢复这个快照到另一个可用区
Redshift安全
- Redshift传输过程中使用SSL加密
- Redshift使用AES-256进行加密
- 默认情况下Redshift帮我们解决了秘钥管理的问题
- 我们也可以使用自己的秘钥
- 或者使用AWS Key Management Service (KMS)来管理秘钥
Elasticache简介
Elasticache是AWS提供的分布式内存对象缓存系统,可以有效地提升现有应用程序的性能。利用Elasticache,用户可以从高吞吐和低延迟的内存数据存储中检索数据。
Elasticache通过在内存中缓存数据来减少对象读取数据库的次数,减轻了数据库的负载,以及提高了网站的访问速度(内存的访问速度比磁盘的访问速度高很多)。一般来说我们会把相对来说更新频繁的“热数据”放在Elasticache中,把“冷数据”还是放在数据库中,以支持及时的更新。
重点:Elasticache是存储在内存中的,是一种in-memory cache系统。
目前Elasticache支持两种业界流行的引擎,分别是:
- Memcached
- Memcached是一套高性能、分布式内存对象缓存系统,是一款开源的,非常流行的缓存系统
- 使用AWS Elasticache可以和Memcached无缝地兼容
- Redis
在实际场景中,如果我们有对数据库的读写有很高的要求,并且数据的更新没有那么频繁,我们就可以考虑使用Elasticache来减少我们的数据库负担,增加数据库读取的性能。
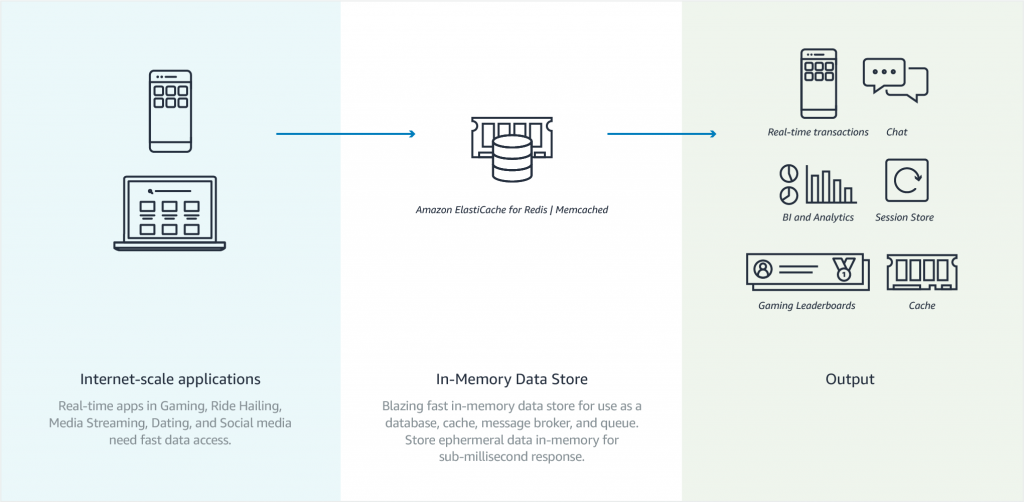
当然,我们也可以使用上一章节将的Read Replicas来解决同样的事情。但不同的是Elasticache是缓存数据库的内容,Read Replicas会异步地同步数据库的内容。另一个不同是,Elasticache是存储在内存中的,因此比起构建在SSD的Read Replicas会快不止一个数量级。
Aurora简介
Amazon Aurora是一种兼容MySQL和PostgreSQL的商用级别关系数据库,它既有商用数据库的性能和可用性(比如Oracle数据库),又具有开源数据库的成本效益(比如MySQL数据库)。
Aurora的速度可以达到MySQL数据库的5倍,同时它的成本只是商用数据库的1/10。
Aurora和其他RDS服务类似,AWS会负责各种管理任务,例如硬件、数据库补丁和数据库备份等。
另外,Aurora还有以下这些特点:
- 10GB的起始存储空间,可以增加到最大64TB的容量
- 计算资源可以提升到最多32vCPU和244GB的内存
- Aurora会将你的数据复制2份到每一个可用区内,并且复制到最少3个可用区,因此你会有6份数据库备份
- 2份及以下的数据备份丢失,不影响Aurora的写入功能
- 3份及以下的数据备份丢失,不影响Aurora的读取功能
- Aurora有自动修复的功能,AWS会自动检查磁盘错误和数据块问题并且自动进行修复
- 有两种数据库只读副本
- Aurora Replicas(最多支持15个)
- MySQL Replica(最多支持5个)
- 两者的区别是Aurora主数据库出现故障的时候,Aurora Replicas可以自动变成主数据库,而MySQL Replica不可以
总结
Multi-AZ高可用
使用Multi-AZ部署模式,RDS会在不同的可用区内配置和维护一个主数据库和一个备用数据库,主数据库的数据会自动复制到备用数据库中。
在开启Multi-AZ的情况下,这个URL Endpoints会根据主/备数据库的健康状态自动解析到IP地址。对于应用程序来说,我们只需要连接这个URL地址即可。
高可用的设置只是用来解决灾备的问题,并不能解决读取性能的问题;要提升数据库读取性能,我们需要用到Read Replicas。
只读副本(Read Replicas)
我们可以在源数据库实例的基础上,复制一种新类型的数据库实例,称之为只读副本(Read Replicas)。我们对源数据库的任何更新,都会异步更新到只读副本中。
因此,我们可以将应用程序的数据库读取功能转移到Read Replicas上,来减轻源数据库的负载。
官方FAQ
强烈建议研读官方FAQ,可以对AWS RDS的概念和实际使用场景有更深入的了解