https://www.examtopics.com/discussions/amazon/view/35837-exam-aws-certified-solutions-architect-associate-saa-c02/
Amazon 资源名称 (ARN)
Amazon 资源名称 (ARN) 唯一标识 AWS 资源。当您需要在 AWS 全局环境中(比如 IAM 策略、Amazon Relational Database Service (Amazon RDS) 标签和 API 调用中)明确指定一项资源时,我们要求使用 ARN。
Amazon FSx
Amazon FSx 使您能以轻松且经济高效的方式启动和运行由 AWS 云完全托管的常用文件系统。借助 Amazon FSx,您可以利用广泛使用的、以商业形式许可的开源文件系统的丰富功能和快速性能,同时避免硬件预置、软件配置、修补和备份等耗时的管理任务。它提供了具有成本效益的容量和极高的可靠性,并与广泛的 AWS 服务组合集成,有助于更快进行创新。
Amazon FSx 提供了两种文件系统可供选择:适用于业务应用程序的 Amazon FSx for Windows File Server 和适用于计算密集型工作负载的 Amazon FSx for Lustre。
非关系数据库DynamoDB v.s. Aurora
DynamoDB是一种非关系数据库(NoSQL),可在任何规模提供可靠的性能。DynamoDB能在任何规模下实现不到10毫秒级的一致相应,并且它的存储空间无限。 数据分散在3个不同地理位置的数据中心(并不是3个可用区)
Amazon Aurora是一种兼容MySQL和PostgreSQL的商用级别关系数据库,它既有商用数据库的性能和可用性(比如Oracle数据库),又具有开源数据库的成本效益(比如MySQL数据库)。 Aurora会将你的数据复制2份到每一个可用区内,并且复制到最少3个可用区,因此你会有6份数据库备份。Aurora跨Region复制整个数据库,而不是table;Aurora复制到单个region, 而不是多个region; Aurora是一写多读,不能多个region同时读写。
EC2置放群组(Placement Group)
在您启动新的 EC2 实例时,EC2 服务会尝试以某种方式放置实例,以便将所有实例分布在基础硬件上以最大限度减少相关的故障。 建议将集群置放群组用于可受益于低网络延迟和/或高网络吞吐量的应用程序。 分布置放群组是一组具有以下特点的实例:每个实例放置在不同的机架上,并且每个机架具有各自的网络和电源。 一个集群置放群组不能跨过多个可用区。
VPN CloudHub
使用 VPN CloudHub 在各个站点之间建立安全通信。
如果您有多个 AWS 站点到站点 VPN 连接,您可以使用 AWS VPN CloudHub 在各个站点之间建立安全通信。这可使您的远程站点彼此进行通信,而不只是与 VPC 进行通信。VPN CloudHub 在简单的星型拓扑连接模型上操作,您可以在使用或不使用 VPC 的情况下操作 VPN CloudHub。如果您有多间分公司和现有 Internet 连接,并且想实施方便、潜在低成本的星型拓扑连接模型,以便在这些远程办公室之间建立主要或备用连接,则该设计会很适用。
站点的 IP 范围不得重叠。
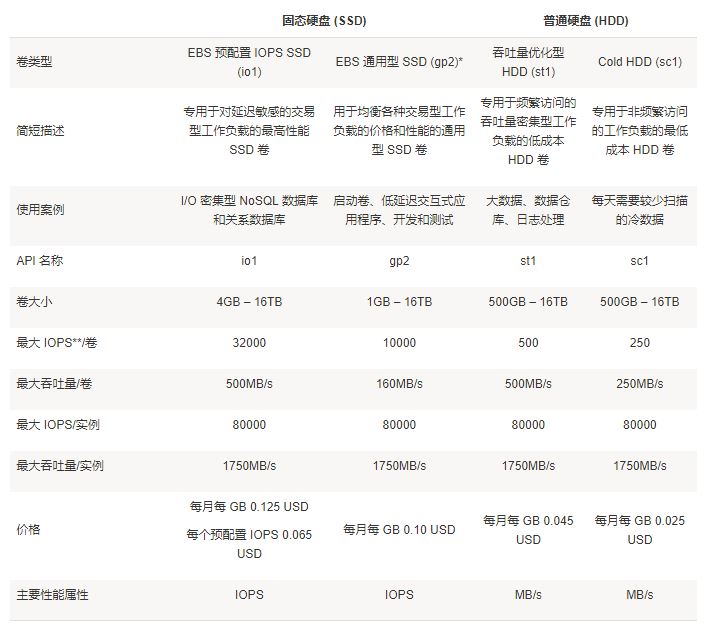
Amazon EBS 优化的实例 optimized SLA
吞吐优化 HDD (st1) 和Cold HDD (sc1) 都可确保 99% 的时间内 90% 突增性能的性能一致性。不合规时间近似均匀分配,目标是达到 99% 的每小时预计总吞吐量
AS Policy
目标跟踪扩展策略 Amazon EC2 Auto Scaling: 可以选择一个扩展指标并设置一个目标值。Amazon EC2 Auto Scaling 创建和管理触发扩展策略的 CloudWatch 警报,并根据指标和目标值计算扩展调整。扩展策略根据需要增加或减少容量,将指标保持在指定的目标值或接近指定的目标值。除了将指标保持在目标值附近以外,目标跟踪扩展策略还会对由于负载模式变化而造成的指标变化进行调整。
- 配置目标跟踪扩展策略,使 Auto Scaling 组的平均聚合 CPU 利用率保持在 40%。
- 为 应用程序负载均衡器 组配置目标跟踪扩展策略,使 Auto Scaling 目标组的每目标请求数保持在 1000。
Step and simple scaling policies
您可以为触发扩展过程的 CloudWatch 警报选择扩展指标和阈值。您还可以定义在指定数目的评估期内违反阈值时应如何扩展 Auto Scaling 组。
AWS Global Accelerator
使用 AWS 全球网络提升全球应用程序的可用性和性能。AWS Global Accelerator 是通过 Amazon Web Service 的全球网络基础设施发送您的用户流量的联网服务,将您的互联网用户性能提升了高达 60%。当互联网拥塞时,Global Accelerator 的自动路由优化会帮助您将数据包丢失、抖动和延迟水平持续维持在低水平。
AWS Global Accelerator 为您提供静态 IP 地址,作为托管在一个或多个 AWS 区域中的应用程序的固定入口点。 凭借 Global Accelerator,您可获得两个面向客户的全球静态 IP,以简化流量管理。在后端,增加或删除您的 AWS 应用程序源,如 Network Load Balancers、Application Load Balancers、弹性 IP 和 EC2 实例,无需作出面向用户的更改。为减少终端节点故障,Global Accelerator 自动将您的流量重新路由至您最近的正常运行的可用终端节点。
AWS EC2如何精确计算每小时成本?(How exactly does AWS EC2 count hourly costs?)
Pricing is per instance-hour consumed for each instance, from the time an instance is launched until it is terminated or stopped. Each partial instance-hour consumed will be billed as a full hour. 从启动实例
到终止实例或停止实例,每个实例每小时消耗的实例价格。所消耗的每个
部分实例小时都将按一个小时计费。
除非您计算的时间不超过免费套餐的最低阈值,即您使用一小时付费的EC2实例的第二个阈值。如果您在第一个小时内花了一秒钟,那么第二个小时便要收费。
一个警告:竞价型实例。
如果在使用一小时之前,现货实例被AWS(不是您)中断了,则完全不会向您收费。如果您中断了竞价型实例,则需要支付部分小时的使用费(根据请求的实例,该时间为一整小时)。
EBS和EC2 Instance storage的区别
实例存储比较适合存放短暂型、变化很快的数据,比方说缓存、爬虫数据和其他短暂的数据。例子是视频处理,使用本地10TB存储,最大IO性能。
The good news is: many of the newer EC2 instances (i.e. i3, m5d, etc) have local SSD disks attached (NVMe). Those disks are local to the physical server and should not suffer from the EBS issues described above. Using local disks can be a very good solution:
- They are faster, as they are local to the server, and do not suffer from the EBS issues
- They are much cheaper compared to large EBS volumes.
Please note, however, that local storage does not guarantee persistence.
AWS WAF
AWS WAF 是一个 Web 应用程序防火墙,可帮助保护 Web 应用程序和 API 免受攻击。 您可以使用 AWS WAF 保护 API Gateway API 免受常见的 Web 漏洞攻击,例如 SQL 注入和跨站点脚本 (XSS) 攻击。 在希望允许或阻止请求时指定的条件。
您可以将 AWS WAF 作为 CDN 解决方案的一部分部署到 Amazon CloudFront 上,也可以将其部署到位于 Web 服务器或来源服务器(运行于 EC2 上)之前的 Application Load Balancer、适用于您的 REST API 的 Amazon API Gateway 或者是适用于您的 GraphQL API 的 AWS AppSync 上。
- 要基于请求是否表现为包含恶意脚本允许或阻止请求,请创建跨站点脚本匹配条件。有关更多信息,请参阅使用跨站点脚本匹配条件.
- 要基于请求源自的 IP 地址允许或阻止请求,请创建 IP 匹配条件。有关更多信息,请参阅使用 IP 匹配条件.
- 要基于请求源自的国家/地区允许或阻止请求,请创建地理匹配条件。有关更多信息,请参阅使用地理匹配条件.
- 要基于请求是否超过指定长度允许或阻止请求,请创建大小约束条件。有关更多信息,请参阅使用大小约束条件.
- 要基于请求是否表现为包含恶意 SQL 代码允许或阻止请求,请创建 SQL 注入匹配条件。有关更多信息,请参阅使用 SQL 注入匹配条件.
- 要基于出现在请求中的字符串允许或阻止请求,请创建字符串匹配条件。有关更多信息,请参阅使用字符串匹配条件.
- 要基于出现在请求中的正则表达式模式允许或阻止请求,请创建正则表达式匹配条件。有关更多信息,请参阅使用正则表达式匹配条件.
- Web Application Firewall (WAF) 可以与 API 访问/集成
Amazon DynamoDB Accelerator (DAX)
Amazon DynamoDB Accelerator (DAX) 是适用于 Amazon DynamoDB 的完全托管且高度可用的内存中的缓存,可实现高达 10 倍的性能提升(从数毫秒缩短到数微秒),即使在每秒处理的请求数量达到数百万个的情况下也是如此。
DAX 负责完成为 DynamoDB 表进行内存中的加速所需的所有繁重任务,使开发人员无需管理缓存失效、数据填充或集群管理。
DynamoDB Streams & On-Demand
Amazon DynamoDB 按需模式 : 这是一个灵活的 DynamoDB 新收费模式,无需任何容量规划即可每秒处理数以千计的请求。DynamoDB 按需模式为读写请求提供按请求量付费的定价模式,从而让您只需为使用的资源付费,轻松平衡成本和性能。
DynamoDB 流 是一种有关 DynamoDB 表中的项目更改的有序信息流。当您对表启用流时,DynamoDB 将捕获有关对表中的数据项目进行的每项修改的信息。 每当应用程序在表中创建、更新或删除项目时,DynamoDB 流 都将编写一条具有已修改项目的主键属性的流记录。流记录 包含有关对 DynamoDB 表中的单个项目所做的数据修改的信息。您可以配置流,以便流记录捕获其他信息,例如已修改项目的“前”和“后”图像。 DynamoDB 流 保存24小时。
S3 Batch Operation, Amazon S3 批量操作
S3 批量操作是 Amazon S3 数据管理功能,可让您在 Amazon S3 管理控制台中单击几下或者发出单个 API 请求即可大规模管理数十亿个对象。利用这一功能,您可以更改对象元数据和属性,或执行其他存储管理任务,例如在存储桶之间复制对象、替换对象标记集、修改访问控制以及从 S3 Glacier 还原存档对象 – 而不用花数月时间开发自定义应用程序来执行这些任务。 对于新对象,使用 S3 事件和 Lambda 函数非常适合转换文件类型,创建缩略图,执行数据扫描和执行其他操作。
S3存储桶策略(S3 Bucket Policies)
通常来讲,在使用AWS时,一个和权限、策略相关的服务是IAM,它被用于在AWS账户下分配用户、组、角色使用资源的权限,您可以使用IAM为用户分配访问资源权限,然而,用户策略是用来管理您账户中用户的权限的。对于其他 AWS 账户或其他账户中用户的跨账户权限,则必须使用存储桶策略,而且,当您想基于存储桶来规划访问策略时就需要使用存储桶策略,存储桶策略是直接附加到存储桶上的。
什么是AWS Athena
Amazon Athena 是一种交互式查询服务(Kinesis data Analytics是实时查询),让您能够轻松使用标准 SQL 直接分析 Amazon S3 中的数据。只需在 AWS 管理控制台中单击几下,客户即可将 Athena 指向自己在 S3 中存储的数据,然后开始使用标准 SQL 执行临时查询并在数秒内获取结果。Athena 没有服务器服,因此没有需要设置或管理的基础设施,客户只需为其执行的查询付费。您可以使用 Athena 处理日志、执行即席分析以及运行交互式查询。Athena 可以自动扩展并执行并行查询,因此可快速获取结果,对于大型数据集和复杂查询也不例外。
Route53 地理位置临近度路由(Geo-proximity Routing Policies)
在AWS Route53中有多种不同的路由策略(Routing Policy),我们可以根据自己的不同需求将我们的DNS解析到不同的目标上去。
- 简单路由策略(Simple Routing Policy):提供单一资源的策略类型,即一个DNS域名指向一个单一目标
- 加权路由策略(Weighted Routing Policy):按照不同的权值比例将流量分配到不同的目标上去
- 延迟路由策略(Latency Routing Policy):根据网络延迟的不同,将与用户延迟最小的结果应答给最终用户
- 地理位置路由策略(Geolocation Routing Policy):根据用户所在的地理位置,将不同的目标结果应答给用户
- 地理位置临近度路由(Geo-proximity Routing Policies): 当您希望根据资源的位置路由流量时使用,并且可以选择将流量从一个位置的资源转移到另一个位置的资源。 Geoproximity routing允许Amazon根据用户和资源的地理位置将流量路由到您的资源。
- 故障转移路由策略(Failover Routing Policy):配置主动/被动(Active/Passive)的故障转移策略,保证DNS解析的容灾
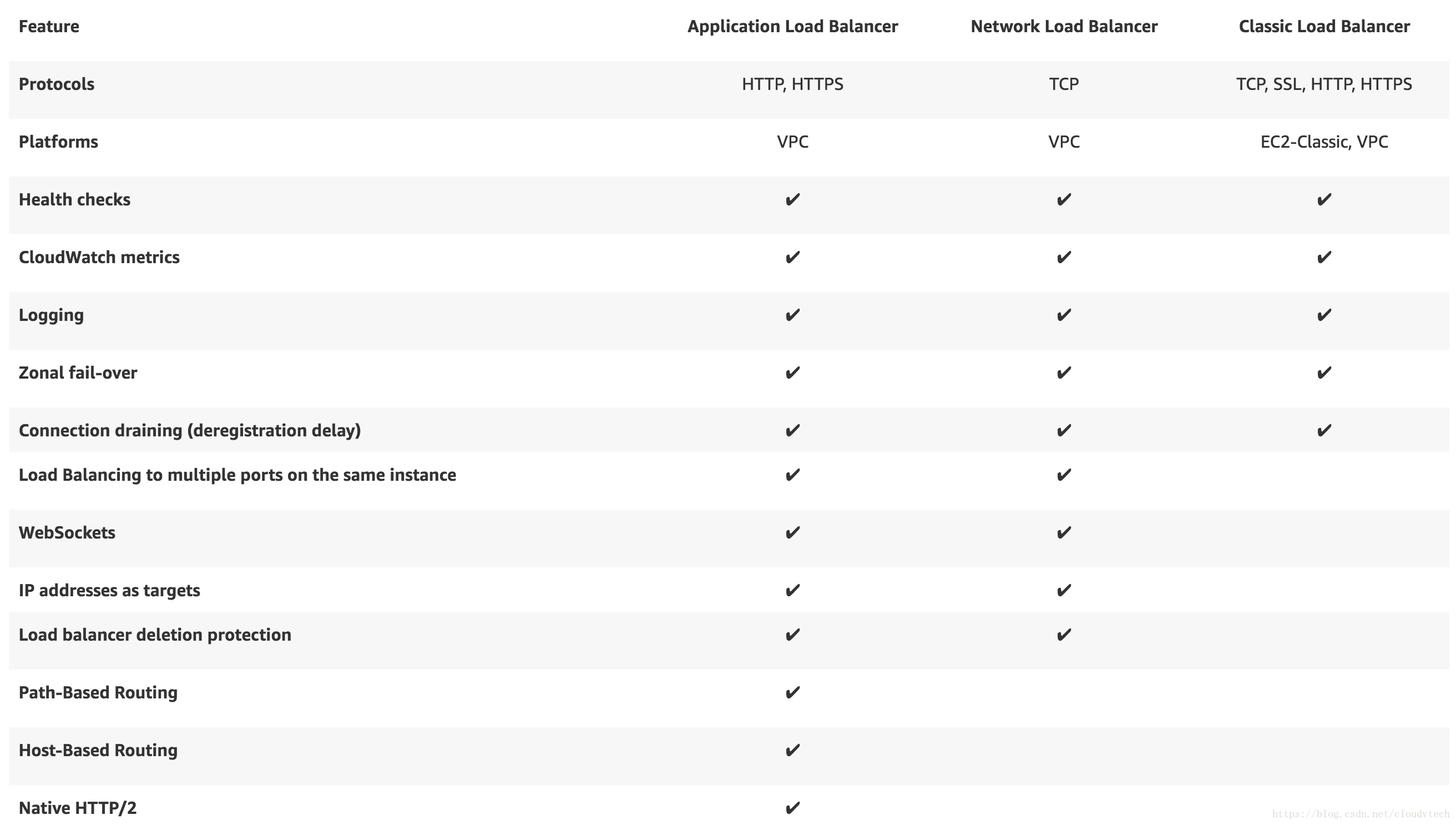
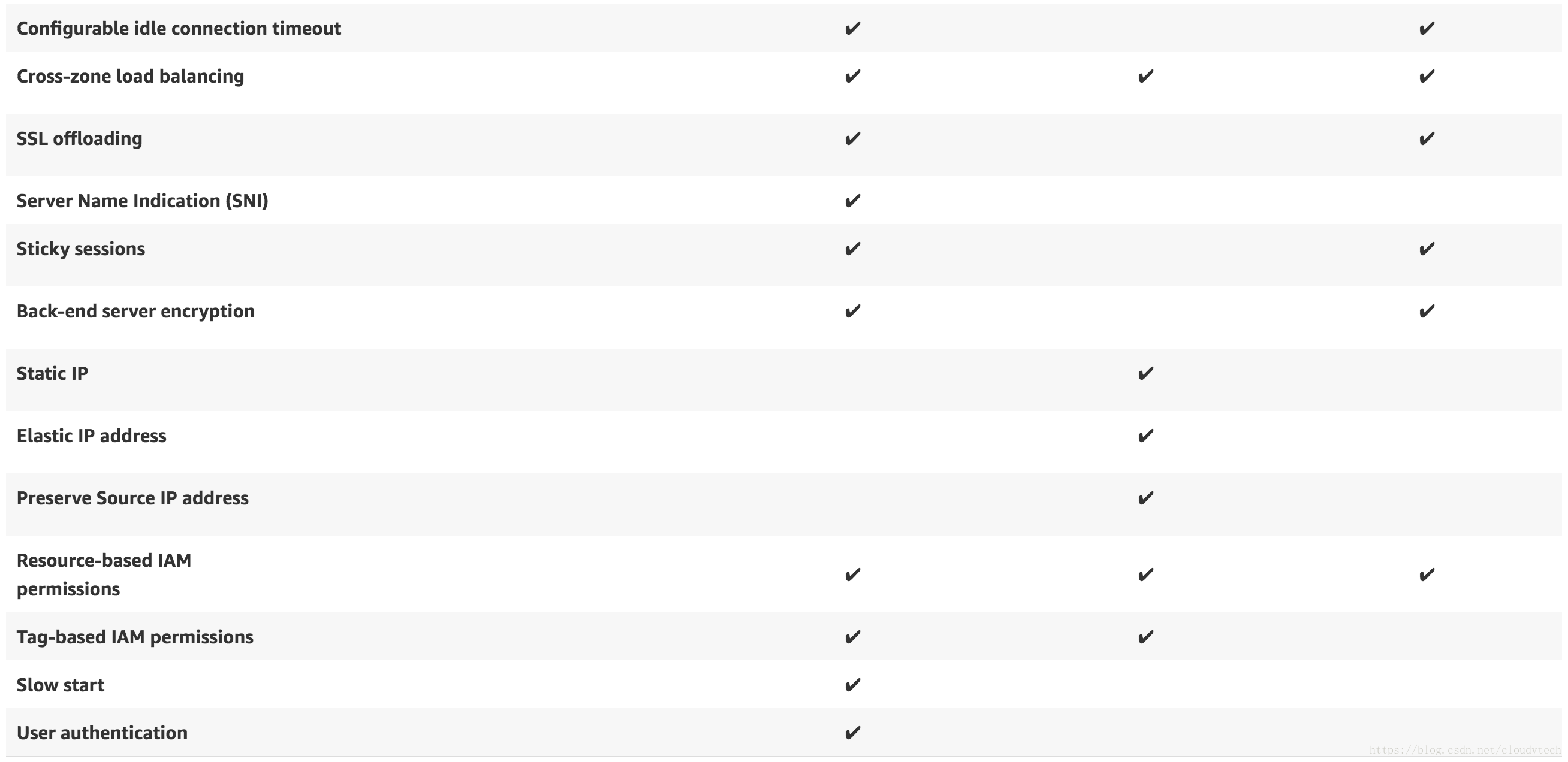
NLB EIP
只有NLB能挂在EIP
Amazon Neptune
Amazon Neptune 是一项快速、可靠且完全托管的图形数据库服务,可帮助您轻松构建和运行使用高度互连数据集的应用程序。Amazon Neptune 的核心是专门构建的高性能图形数据库引擎,它进行了优化以存储数十亿个关系并将图形查询延迟降低到毫秒级。 Amazon Neptune 支持常见的图形模型 Property Graph 和 W3C 的 RDF 及其关联的查询语言 Apache TinkerPop Gremlin 和 SPARQL,从而使您能够轻松构建查询以有效地导航高度互连数据集。Neptune 支持图形使用案例,如建议引擎、欺诈检测、知识图谱、药物开发和网络安全。
Amazon Neptune 具有高可用性,并提供只读副本、时间点恢复、到 Amazon S3 的持续备份以及跨可用区的复制。Neptune 很安全,可支持 HTTPS 加密客户端连接和静态加密。Neptune 完全托管,因此,您再也无需担心数据库管理任务,例如,硬件预置、软件修补、设置、配置或备份。
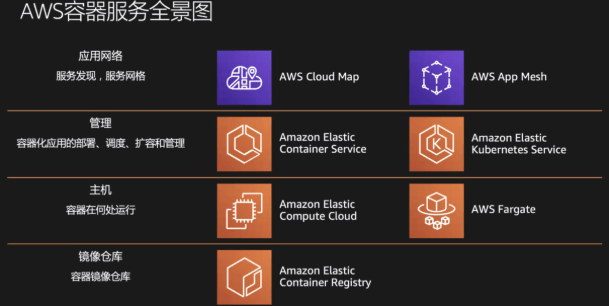
AWS ECS、EKS
2015 年,AWS 率先推出了 Amazon ECS 全托管容器调度管理服务,其为 AWS 原生 Docker 容器解决方案。随后,为了进一步支持开源的 Kubernetes 的发展,相继推出了 Amazon EKS 与 AWS Fargate。
首先最底层 AWS 提供 Amazon ECR 容器镜像仓库的服务;其次,容器可以运行在两种位置上,其一在 Amazon EC2 虚拟机上构建容器服务,其二选择 AWS Fargate 构建无服务器的容器服务;接着,在容器的管理层,AWS 提供 Amazon ECS 和 Amazon EKS 两种方式。最后,在最上层 AWS 支持不同的服务网格和服务发现,包括 Amazon Cloud Map 与 AWS App Mesh。
AWS Config rule
AWS Config 提供了关于您的 AWS 账户中 AWS 资源配置的详细信息。这些信息包括资源之间的关联方式以及资源以前的配置方式,让您了解资源的配置和关系如何随着的时间的推移而更改。
利用 AWS Config,您可以:
- 评估您 AWS 资源配置是否具备所需设置。
- 获得与您的 AWS 账户关联的受支持资源的当前配置快照。
- 检索您的账户中的一个或多个资源配置。
- 检索一个或多个资源的历史配置。
- 在资源被创建、修改或删除时接收通知。
- 查看不同资源之间的关系。例如,您可能想要找到使用特定安全组的所有资源。
Spot Instance v.s. Spot Fleet
Amazon EC2 Spot 实例,是 AWS服务中的可用空闲计算容量。与按需实例的价格相比,这类实例可提供超低折扣。
Spot Fleet 是 Spot 实例 和可选的 按需实例 的集合或队列。 Spot 队列 会尝试启动适当数量的 Spot 实例 和 按需实例,以满足在 Spot 队列 请求中指定的目标容量要求。
Cloudwatch Agent
默认情况下,AWS的监控服务Cloudwatch并没有对EC2内的内存总量和使用情况进行监控,因为内存属于用户操作系统内的信息,在AWS的产品设计中,所有系统内的信息都属于用户的私有财产和信息。所以默认情况下,AWS的Cloudwatch不收集相关信息。
但在实际使用的项目中,以内存监控为代表的系统、应用层面的监控是系统监控中的非常重要的一环,所以AWS提供了Cloudwatch Agent来帮助用户将EC2实例中的系统层面的信息,如:内存及其他相关信息通过Cloudwatch展现出来,这些信息的访问权仍然属于用户自己。
事实上,Cloudwatch Agent不仅仅能够收集内存信息,还能在更多系统层面收集信息,比如: CPU Active/Idle time,Disk IO Time,Network的包转发数等等,相比EC2的默认Cloudwatch,它可以提供更为详细和多样性的监控。
S3 One Zone-Infrequent Access
S3 One Zone-Infrequent Access(S3 Z-IA),这是一种新的存储类别,专为那些希望为不经常访问的数据提供成本较低的选项的客户设计,但不需要 S3 Standard 和 S3 Standard-Infrequent Access(S3 S-IA)存储类 借助 S3 Z-IA,客户现在可以在单个可用区内存储不经常访问的数据,成本比 S3 S-IA 低20%。 Amazon S3 Standard,S-IA 和 Amazon Glacier 在至少三个地理位置分散的可用区域之间分布数据,以提供最高级别的 AZ 丢失恢复能力。S3 Z-IA 通过在单个可用区中存储弹性较低的不经常访问的数据来节省成本。
Amazon Trusted Advisor 最佳实践(检查)
Amazon Trusted Advisor 的作用类似于自定义云专家,帮助您按照以下最佳实践来配置资源。Trusted Advisor 会检查您的亚马逊云科技环境,并发现可以节省开支、提高系统性能和可靠性或帮助弥补安全漏洞的机会。 Amazon Trusted Advisor 提供了以下四种类别的最佳实践:成本优化、安全、容错能力和性能提升。
Amazon EC2 基于 Nitro 系统的实例现在支持更快的 Amazon EBS 优化型实例性能
借助 Nitro 系统的最新增强功能,我们将最大 EBS 优化型实例带宽增至 14Gbps,C5/C5d 和 M5/M5d 最初分别是 9Gbps 和 10Gbps。我们还针对 Nitro 系统将最大 EBS 优化型实例 IOPS 增至 80000 个 IOPS,C5/C5d 和 M5/M5d 最初分别是 64000 个 IOPS 和 65000 个 IOPS。此外,我们还将 large、xlarge 和 2xlarge C5/C5d 和 M5/M5d 实例的 EBS 优化型实例突增性能提升至 3.5Gbps,最初分别是 2.25Gbps 和 2.12Gbps。
AWS CloudHSM 您控制和管理自己的密钥
AWS CloudHSM 让您可以通过安全渠道访问 HSM,以创建用户并设置 HSM 策略。您通过 CloudHSM 生成和使用的加密密钥只能由您指定的 HSM 用户访问。AWS 无法访问或使用您的加密密钥。
AWS KMS 与大多数加密您的数据的其他 AWS 服务集成。 AWS KMS 还与 集成AWS CloudTrail以记录您的 的使用CMKs,从而满足审计、监督和合规性需求。 通过使用 CloudTrail ,您可以监控和调查哪些人在何时以何种方式CMKs使用了。
AWS Glue
AWS Glue 是一项完全托管的 ETL(提取、转换和加载)服务,使您能够轻松而经济高效地对数据进行分类、清理和扩充,并在各种数据存储和数据流之间可靠地移动数据。
Amazon EFS 生命周期管理
Amazon EFS 生命周期管理自动针对您的文件系统管理经济高效的文件存储。启用后,生命周期管理会将在一段设定时间内未访问的文件迁移到 EFS –StandardInfrequent Access (Standard-IA) 或 One –ZoneInfrequent Access (One Zone-IA) 存储类,具体取决于您的文件系统。
S3 Cross-region replication不复制已经存在的文件
复制将针对新创建的对象进行, 如果大家需要对现有对象进行复制,则可以利用S3COPY操作建立解决方案,从而保证目标存储桶内的内容得以更新。
Amazon RDS 现在支持 Storage Auto Scaling
Amazon RDS for MariaDB、Amazon RDS for MySQL、Amazon RDS for PostgreSQL、Amazon RDS for SQL Server 和 Amazon RDS for Oracle 支持 RDS Storage Auto Scaling。RDS Storage Auto Scaling 会自动扩展存储容量,以响应不断增加的数据库工作负载,而不造成停机。 之前,您必须根据预期的应用程序需求手动预置存储容量。预置不足可能会导致应用程序停机,而预置过剩则可能致使资源利用率过低以及成本较高。使用 RDS Storage Auto Scaling,您只需设置所需的存储上限,其余的由 Auto Scaling 负责。
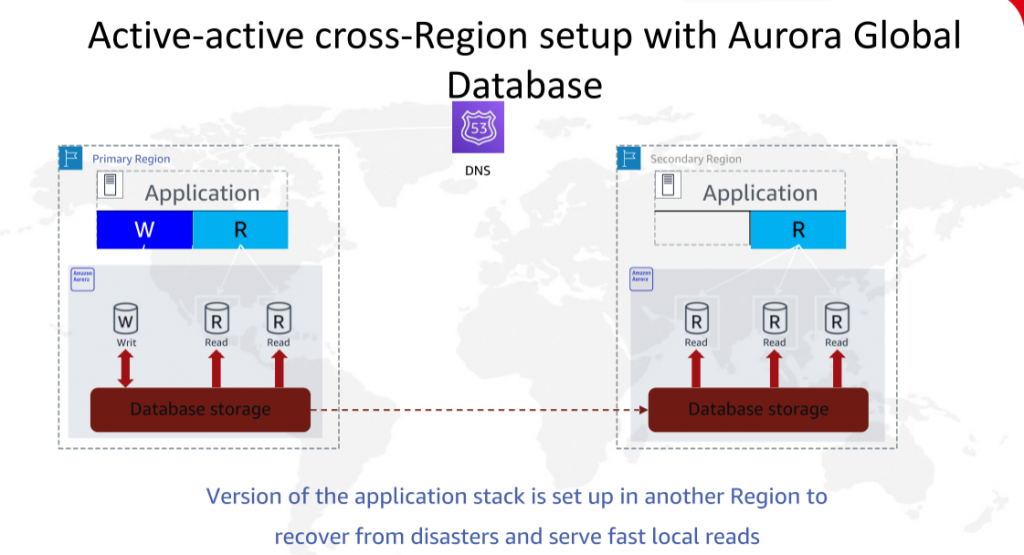
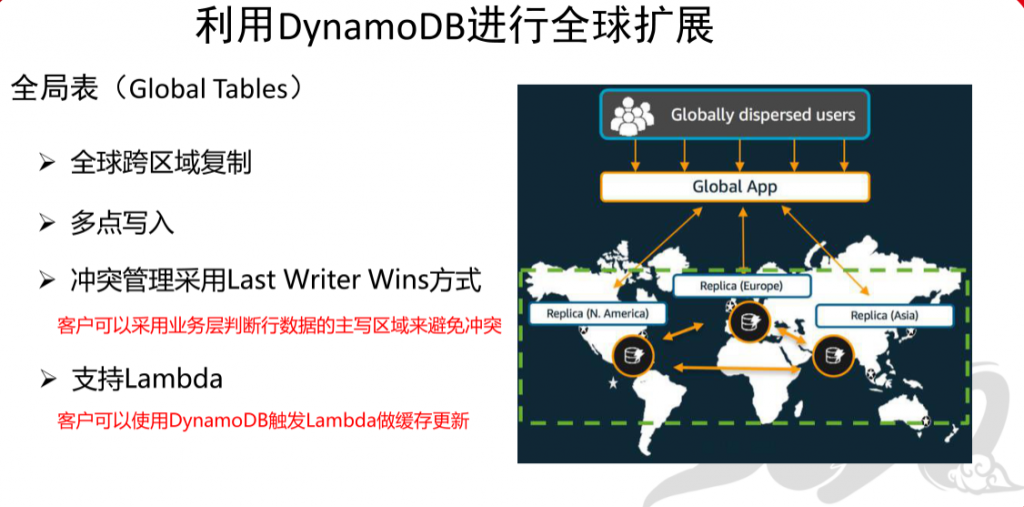
Aurora Global Databases V.S. DynamoDB Global Tables
Aurora Global Databases 一写多读, 毫秒级同步
DynamoDB Global Tables 多点写入
AWS Shield 托管式 DDoS 防护
所有 AWS 客户都可以使用 AWS Shield Standard 的自动防护功能,不需要额外支付费用。AWS Shield Standard 可以防护大多数以网站或应用程序为攻击对象并且频繁出现的网络和传输层 DDoS 攻击。将 AWS Shield Standard 与 Amazon CloudFront 和 Amazon Route 53 一起使用时,您将获得针对所有已知基础设施(第 3 层和第 4 层)攻击的全面可用性保护。
AWS Shield Advanced 还可以针对复杂的大型 DDoS 攻击提供额外的检测和缓解服务,让您能够近实时查看各种攻击,并且集成了 AWS WAF 这一 Web 应用程序防火墙。 您的源服务器可以是 Amazon S3、Amazon Elastic Compute Cloud (EC2)、Elastic Load Balancing (ELB) 或 AWS 外部的自定义服务器。您还可以在以下 AWS 区域直接在弹性 IP 或 Elastic Load Balancing (ELB) 上启用 AWS Shield Advanced。
AWS Organizations
AWS Organizations 是一项账户管理服务,使您能够将多个 AWS 账户整合到您创建并集中管理的组织 中。AWS Organizations 包含账户管理和整合账单功能,可利用这些功能更好地满足企业的预算、安全性和合规性需求。作为组织的管理员,您可以在组织中创建账户并邀请现有账户加入组织。
集中控制每个账户可访问AWS的服务和 API 操作的策略 service control policy: 作为组织管理账户的管理员,您可以使用服务控制策略 (SCPs) 指定组织中成员账户的最大权限。 当 AWS Organizations 阻止对某个成员账户对服务、资源或 API 操作的访问时,该账户中的用户或角色将无法访问它。即使成员账户的管理员在 IAM 策略中明确授予此类权限,此阻止仍然有效。
Kinesis服务
Kinesis目前有不同的功能服务,我们需要了解每一个服务有什么不同。这些服务分别是:
- Kinesis Data Streams (Kinesis Streams):使用自定义的应用程序分析数据流
- Kinesis Video Streams:捕获、处理并存储视频流用于分析和机器学习(Machine Learning)
- Kinesis Data Firehose:将数据加载到AWS数据存储上
- Kinesis Data Analytics:使用SQL分析数据流(Athena是交互式查询)
Amazon Lambda 支持运行时间长达 15 分钟的函数
您现在可以将函数的超时设置为不超出 15 分钟的任何值。在达到指定超时时,Amazon Lambda 会终止 Lambda 函数的执行。按照最佳实践,您应该基于预计执行时间设置超时值,以防止函数运行时间超出预期。
CloudTrail data events v.s. s3 server access log
在AWS SAA C01的官方备考书中提及CloudTrail data events可以记录S3 object-level activity 而且根据网上的文档,CloudTrail和s3 server access log都能够记录对象操作,但是Cloud Trail能提供一致性验证,s3 server access log不能。(https://docs.aws.amazon.com/zh_cn/AmazonS3/latest/dev/logging-with-S3.html中的表格) CloudTrail虽然默认情况下不会记录s3的对象操作,但是可以设置使用数据事件,方法在https://docs.aws.amazon.com/zh_cn/AmazonS3/latest/user-guide/enable-cloudtrail-events.html中。
AWS Glue
AWS Glue 是一项无服务器数据集成服务,它简化了准备数据以进行分析、机器学习和应用程序开发的工作。
AWS Transfer Family
AWS Transfer Family 提供完全托管支持,可将文件直接传入和传出 Amazon S3 或 Amazon EFS。 AWS Transfer Family 支持安全文件传输协议 (SFTP)、SSL 的文件传输协议 (FTPS) 和文件传输协议 (FTP),可通过集成现有身份验证系统并提供与 Amazon Route 53 的 DNS 路由,帮助您将文件传输工作流程无缝迁移到 AWS,而对于客户和合作伙伴及其应用程序而言则没有任何变化。对于 Amazon S3 或 Amazon EFS 中的数据,您可以搭配使用 AWS 服务对其执行数据处理、分析、机器学习和存档,此外还可以利用主目录和开发人员工具。
Aws Inspector, AWS Macie , AWS Trusted Advisor , AWS GuardDuty, AWS Cognito
Amazon Inspector 是一项自动安全评估服务,有助于提高在 AWS 上部署的应用程序的安全性与合规性。 Amazon Inspector 会自动评估应用程序的风险、漏洞或者相较于最佳实践的偏差。执行评估后,Amazon Inspector 会生成按严重程度确定优先级的安全检测详细列表。这些评估结果可直接接受审核,也可作为通过 Amazon Inspector 控制台或 API 提供的详细评估报告的一部分接受审核。
Amazon Macie 是一项完全托管的数据安全和数据隐私服务,它利用机器学习和模式匹配来发现和保护 AWS 中的敏感数据。 随着组织管理越来越多的数据,大规模地识别和保护它们的敏感数据会变得越来越复杂、昂贵和耗时。Amazon Macie 可以大规模自动发现敏感数据,同时降低保护数据的成本。Macie 会自动提供 Amazon S3 存储桶的清单,包括未加密的存储桶、可公开访问的存储桶以及与 AWS 账户共享的存储桶的列表,其中这些账户不属于您在 AWS Organizations 中定义的账户。然后,Macie 将机器学习和模式匹配技术应用于您选择的存储桶,以识别敏感数据,并向您发出警报,例如个人身份信息 (PII)。
AWS Trusted Advisor 是一个在线工具,可提供实时指导,帮助您按照 AWS 最佳实践预置资源。 AWS Basic Support 和 AWS Developer Support 客户可获得 6 次安全检查(S3 存储桶权限、安全组 – 特定端口不受限制、IAM 使用、根账户上的 MFA、EBS 公有快照、RDS 公有快照)和 50 次服务限制检查。AWS Business Support 和 AWS Enterprise Support 客户可获得全部 115 次 Trusted Advisor 检查(14 次成本优化、17 次安全性检查、24 次容错能力检查、10 次性能检查和 50 次服务限制检查)和建议。
Amazon GuardDuty 提供智能威胁检测和持续监控,保护您的 AWS 账户、工作负载和数据。是一种威胁检测服务,可持续监控恶意活动和未经授权的行为,从而保护您的 AWS 账户、工作负载和在 Amazon S3 中存储的数据。 GuardDuty 对来自多个 AWS 数据源(例如 AWS CloudTrail 事件日志、Amazon VPC 流日志和 DNS 日志)的数百亿事件进行分析。
借助 Amazon Cognito,简单安全的用户注册、登录和访问控制。您可以快速轻松地为 Web 和移动应用程序添加用户注册、登录和访问控制功能。 Amazon Cognito 可将用户规模扩展到数百万,并支持通过 SAML 2.0 和 OpenID Connect 使用社交身份提供商(如 Apple、Facebook、Google 和 Amazon)以及企业身份提供商进行登录。
Cloudfront OriginGroup
An origin group includes two origins (a primary origin and a second origin to failover to) and a failover criteria that you specify. You create an origin group to support origin failover in CloudFront. When you create or update a distribution, you can specifiy the origin group instead of a single origin, and CloudFront will failover from the primary origin to the second origin under the failover conditions that you’ve chosen.
NAT instance, NAT Gatrway, internet gateway
AT实例(NAT Instance)
- 创建NAT实例之后,一定要关闭源/目标检查(Source/Destination Check)
- NAT实例需要创建在公有子网内
- 私有子网需要创建一条默认路由(0.0.0.0/0),指到NAT实例
- NAT实例的瓶颈在于实例的大小,如果遇到了网络吞吐瓶颈,你可以加大实例类型
- 需要自己创建弹性伸缩组(Auto Scaling Group),自定义脚本来达到NAT实例的高可用(比如部署在多个可用区)
- 需要关联一个安全组(Security Group)
NAT网关(NAT Gateway)
- 网络吞吐可以达到10Gbps
- 不需要为NAT的操作系统和程序打补丁
- 不需要关联安全组
- 自动分配一个公网IP地址(EIP)
- 私有子网需要创建一条默认路由(0.0.0.0/0)到NAT网关
- 不需要更改源/目标检查(Source/Destination Check)
- 每个AZ都需要一个,因为它们只在一个AZ中运行
Internet Gateway
Internet网关是 logical connection between an Amazon VPC and the Internet . 它不是物理设备 . 每个VPC只能关联一个 . 它不限制Internet连接的带宽 . (带宽的唯一限制是Amazon EC2实例的大小,它适用于所有流量 – VPC内部和Internet . )
如果VPC does not 具有Internet网关,则VPC中的资源 cannot be accessed from the Internet (除非流量通过公司网络和VPN / Direct Connect流动) .
如果子网具有将流量定向到Internet网关的路由表,则该子网被视为 Public Subnet .
gateway分很多种,比如:
nat gateway:network address translate,只能从vpc内部访问internet或者aws services,外部无法访问vpc,这样大大地提高了安全性
vpn gateway:virtual private network,用于通过vpn连接企业的局域网或者数据中心
internet gateway:同internet进行双向通信,一般会给ec2 instance绑定一个elastic ip address用于从外部访问ec2 instance
egress-only gateway:只能从ec2 instance向外访问,并且只适用于ipv6地址的路由,ipv4的话需要使用nat gateway
下面再说一说network interface,如果ec2 instance当作电脑主机的话,network interface相当于网卡,每个ec2 instance可以指定一个或多个network interface,有了网卡,主机才能同外界进行数据通信,而且不同的网卡可以存在于不同的subnet里面
在AWS上使用IPv6的注意事项
- 在 AWS的VPC 中使用 IPv6 不收取任何额外费用。
- 分配给EC2实例的IPv6地址都是全球单播地址,因此不需要NAT 网关。并且IPv6 不支持 NAT 网关。
- Amazon 的弹性IP地址服务(Elastic IP)目前不支持 IPv6 地址。对于指向实例的常规IPv6地址,该地址对于该实例将始终保持不变。
- 如果现有 VPC 仅支持 IPv4 并且子网中的资源配置为仅使用 IPv4,则可为VPC 和资源启用 IPv6 支持。VPC 可在双堆栈模式下运行 —资源可通过 IPv4 和/或 IPv6 进行通信。IPv4 和 IPv6 通信彼此独立。
- 目前不能为 VPC 和子网禁用 IPv4 支持;这是 Amazon VPC 和 Amazon EC2 的默认 IP 寻址系统。
- 如果使用 Amazon Linux 2016.09.0 或更高版本、Windows Server 2008 R2 或更高版本启动实例,则已经为 IPv6 配置实例,无需执行其他步骤。
- 关于域名服务,Amazon Route 53 支持正向 (AAAA) 和反向 (PTR) IPv6 记录。Amazon Route 53 服务本身也可通过 IPv6 使用。IPv6 网络上的递归 DNS 解析器可以使用 IPv4 或 IPv6 传输,以便向 Amazon Route 53 提交 DNS 查询。Amazon Route 53 运行状况检查也支持使用 IPv6 协议来监控终端节点。
- 尽管大部分AWS服务都支持了IPv6,仍有少量服务不支持IPv6,例如RDS。
- 自带 IP 地址 (BYOIP)服务目前仅支持IPv4,尚不支持IPv6。
Elastic Fabric Adapter
Elastic Fabric Adapter (EFA) 是一种网络设备,可以将其附加到 Amazon EC2 实例以加速高性能计算 (HPC) 和机器学习应用程序。通过使用 EFA,您可以实现本地 HPC 集群的应用程序性能,并具有 AWS 云提供的可扩展性、灵活性和弹性。
AWS CloudFormation与BeanStalk的联系与区别
CloudFormation与BeanStalk都可以用来调用云资源和服务,也可以做相同的一件事情,他们的区别如下:
1.CloudFormation面向的是开发者,BeanStalk面向的是应用程序
2.CloudFormation是为做某件事情而整合资源,BeanStalk是为某个应用程序而整合资源。
3.使用CloudFormation要比使用BeanStalk复杂得多,CloudFormation的配置模版是一份json数据,这个对于不懂编程的人来说很难应用!BeanStalk可以通过界面向导来配置。
AWS Billing and Cost Management
AWS Billing and Cost Management 是您用來支付 AWS 帳單、監控用量,以及分析和控制成本的 服務。
使用 分析成本 Cost Explorer: 用于以图表形式查看您的 AWS 成本数据。使用 Cost Explorer,您可以根据一系列值来筛选图表,例如 API 操作、可用区、AWS 服务、自定义成本分配标签、Amazon EC2 实例类型、购买选项、AWS 区域、使用类型、使用类型组,等等。如果您使用整合账单功能,还可以按成员账户筛选。另外,您可以看到基于历史成本数据预测的未来成本。
AWS Budgets: Budgets 使用 Cost Explorer 提供的直观成本图表来显示您的预算状态。
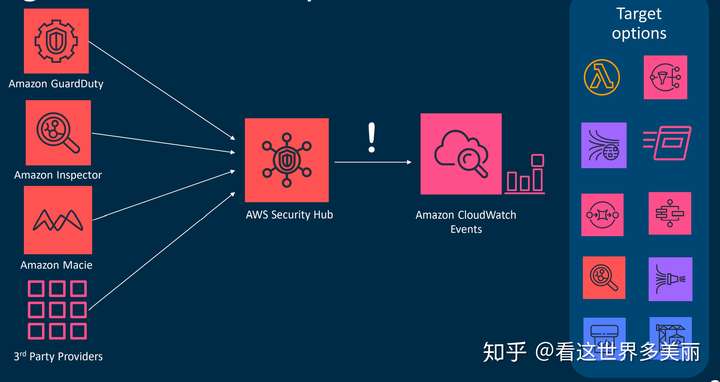
AWS Security Hub
AWS Security Hub 让您全面了解 AWS 账户中的高优先级安全警报与合规性状态。 借助 Security Hub,您现在可以设置单个位置,聚合、组织和优先处理来自多个 AWS 服务(如 Amazon GuardDuty,Amazon Inspector 和 Amazon Macie),以及来自 AWS 合作伙伴解决方案的安全警报或检测结果。
S3 IAM Policy , 桶策略(Bucket Policy)和访问控制列表(Access Control Lists)
AWS S3的权限设置一直是一个重难点,而且是比较混淆的一个概念。比较混淆的地方在于,用户可以通过三个不同的地方进行权限管理,这三个地方分别是 IAM Policy, Bucket Policy 以及 Bucket ACL。
首先简单的说明一下他们的应用场景,IAM Policy是global级别的,他是针对用户来设置的,比如一个用户对所有的S3Bucket拥有get和list权限,那他就可以浏览任何一个Bucket的内容; 相较而言,S3 Bucket Policy仅仅是针对单个Bucket 而言的,他可以控制不同用户对他本身的访问权限;Bucket ACL是一个早期的服务,现在用的比较少了,但是如果我们需要对Bucket其中的具体对象配置访问权限,我们需要使用Bucket ACL。
- 默认情况下,所有新创建的S3存储桶都是私有的,只有存储桶的创建者/拥有者才能访问
- 你可以通过桶策略(Bucket Policy)和访问控制列表(Access Control Lists)两个方法来控制S3存储桶的安全性
- S3存储桶的访问日志可以存到另一个S3存储桶里面,方便对日志进行查看
Amazon S3 Transfer Acceleration
您可以使用 Amazon S3 Transfer Acceleration 在您的客户端和 S3 存储桶之间进行快速、轻松、安全的远距离文件传输。Transfer Acceleration 使用 Amazon CloudFront 中的全球分布式边缘站点。当数据到达某个边缘站点时,数据会被经过优化的网络路径路由至 Amazon S3。
Security Groups has no Deny rule
- Default Security group allows no external inbound traffic but allows inbound traffic from instances with the same security group
- Default Security group allows all outbound traffic
- New Security groups start with only an outbound rule that allows all traffic to leave the instances
- can specify only Allow rules, but not deny rules
- are Stateful
AWS Auto Scaling 在缩小的过程中默认的终止策略
默认终止策略旨在帮助确保在可用区之间平均分配实例,以获得高可用性。默认策略会保留通用性和灵活性,旨在满足各种场景的需要。
默认终止策略行为如下所示:
- 确定哪些可用区包含最多实例,并且至少有一个实例不受缩减保护。
2. 确定要终止的实例,以便使剩余实例与要终止的按需实例或 Spot 实例的分配策略保持一致。这仅适用于指定了分配策略的 Auto Scaling 组。
例如,在实例启动后,您将更改首选实例类型的优先级顺序。发生缩减事件时,Amazon EC2 Auto Scaling 尝试从优先级较低的实例类型逐渐转移按需实例。
3. 确定是否有任何实例使用最旧的启动模板或配置:
[适用于使用启动模板的 Auto Scaling 组]
除非存在使用启动配置的实例,否则确定是否有任何实例使用最旧的启动模板。Amazon EC2 Auto Scaling 先终止使用启动配置的实例,然后终止使用启动模板的实例。
[适用于使用启动配置的 Auto Scaling 组]
确定是否有任何实例使用最旧的启动配置。
4. 在应用上述所有条件后,如果要终止多个不受保护的实例,请确定哪些实例最接近下一个计费小时。如果有多个不受保护的实例最接近下一个计费小时,请随机终止其中的一个实例。
Amazon Aurora Multi-Master
Amazon Aurora Multi-Master 现已全面推出,允许您在多个可用区创建不同的 Aurora 数据库读写实例,适用于即使在实例故障时仍可实现连续写操作的正常运行时间敏感型应用。如果出现实例或可用区故障,Aurora Multi-Master 将支持 Aurora 数据库维持读写操作,从而实现零应用停机。借助 Aurora Multi-Master,数据库无需故障转移即可恢复写操作。请查看此博客了解如何使用 Aurora Multi-Master 构建高可用性 MySQL 应用。
Amazon Aurora Serverless
Amazon Aurora Serverless 是 Amazon Aurora 的一种按需自动扩展配置版本。Amazon Aurora Serverless 会根据应用程序的需求自动启动、关闭以及扩展或缩减容量,让您无需管理任何数据库实例,即可在云中运行数据库。
使用案例
不频繁使用的应用程序
有些应用程序每天或每周只使用几次,且每次只使用几分钟,例如低容量的博客网站,因此您需要一种具有成本效益的数据库,让您只需在数据库处于活动状态时付费。借助 Aurora Serverless v1,您只需为所使用的数据库资源付费。
开发和测试数据库
软件开发和 QA 团队在工作时间需要使用数据库,但在夜间或周末不需要。借助 Aurora Serverless v1,您的数据库将在不使用时自动关闭,并在第二天开始工作时更快地启动。
AWS Security Token Service
AWS Security Token Service (AWS STS) 使您能够为 AWS IAM 用户或您通过联合身份验证进行身份验证的用户请求权限受限的临时凭证。
一个常见的临时凭证使用案例是向移动或客户端应用程序授予对 AWS 资源的访问权限,方法是通过第三方身份提供程序对用户进行身份验证
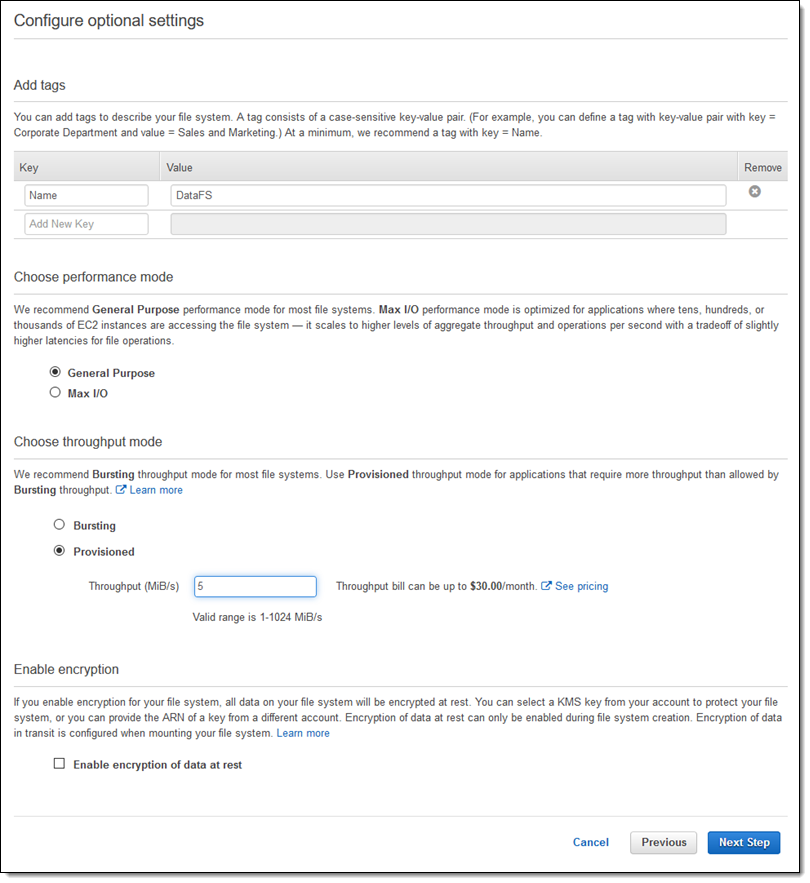
EFS throughput mode V.S. FSx for Lustre throughput
您可以已经知道,EFS 为您在创建文件系统时提供了两种性能模式选择:
通用 — 这是默认的模式,也是您应当首先开始使用的模式。它非常适合对延迟敏感的使用案例,最高支持每个文件系统每秒 7000 次运算。
最大 I/O – 这种模式可扩展至更高的总吞吐量和性能水平,但延迟略高。它本身不存在每秒运算次数限制。
Amazon EFS 提供两种吞吐量模式:突增和预置。吞吐量模式有助于确定文件系统可以实现的整体吞吐量。利用突增吞吐量模式,吞吐量会根据文件系统的大小扩展,同时根据需要动态突增,以支持多个基于文件的工作负载的高峰性质。预置吞吐量模式旨在支持需要比默认突增模式更高专用吞吐量并且可以独立于存储在文件系统上的数据量进行配置的应用程序。
预置吞吐量: 从高吞吐量到不占用整片空间的文件集,可以让许多使用案例受益,例如Web 服务器内容农场、解析树和 EDA 模拟等。为满足这种使用模式的需求,您现在可以选择为您的每个 EFS 文件系统预置期望的吞吐量水平(最高每秒 1 GiB)。您可以在创建文件系统时设置一个初始值,然后在需要时任意增加。您还可以每隔 24 小时将它下调,以及在同一循环的预置吞吐量和突增吞吐量之间切换。例如,您可以将一个 EFS 文件系统配置为向您的 Web 服务器提供每秒 50 MiB 的吞吐量,即使卷包含的内容量相对较小。
如果应用程序的吞吐量要求超过默认(突增)模式的能力,则预置模式将是您的绝佳选择!您可以在创建系统后立即达到期望的吞吐量水平,不论您使用的存储有多高或多低。
Amazon FSx for Lustre 文件系统使用网络I/O信用机制提供突发读取吞吐量,以根据平均带宽利用率分配网络带宽。 https://docs.aws.amazon.com/zh_cn/fsx/latest/LustreGuide/performance.html
部署机制Beanstalk、CloudFormation、 OpsWorks

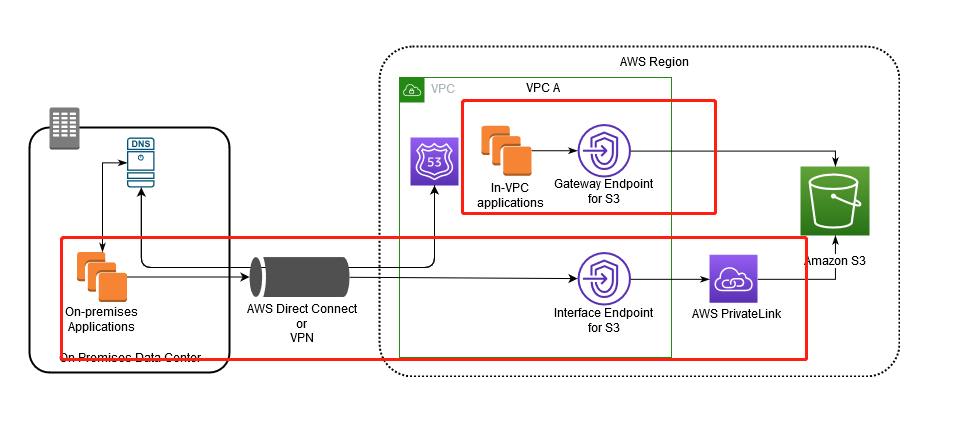
S3 VPC Endpoint Interface V.S. S3 gateway endpoint
https://docs.aws.amazon.com/AmazonS3/latest/userguide/privatelink-interface-endpoints.html

What are the differences between data and management events in CloudTrail?
https://aws.amazon.com/premiumsupport/knowledge-center/cloudtrail-data-management-events/?nc1=h_ls
CloudTrail 数据事件
CloudTrail 默认会禁用数据事件。您可以启用日志记录,但需要额外付费。数据事件也称为数据层面操作,通常都属于较高容量的活动。数据事件无法在 CloudTrail 事件历史记录中查看,所有副本都将按低于管理事件的折扣价格收费。
CloudTrail 管理事件
CloudTrail 免费记录最近 90 天的管理事件,可在 CloudTrail 控制台的“事件历史记录”中查看。对于 Amazon S3 交付的 CloudTrail 事件,交付的第一份副本也是免费的。其他管理事件副本则会收费。管理事件也称为控制层面操作。
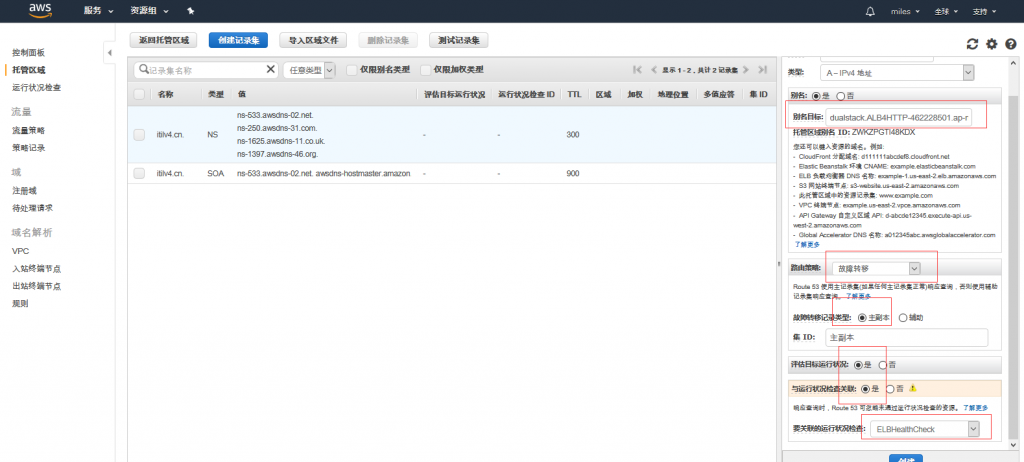
Route53 Evaluate Target Health
如果您希望 Route 53 根据资源的运行状况路由流量,请选择是。
您可以将运行状况检查与别名记录相关联,以作为将 Evaluate Target Health 的值设置为 Yes 的替代或补充。但是,如果 Route 53 根据基础资源的运行状况来响应查询(HTTP 服务器、数据库服务器和您的别名记录引用的其他资源),这样关联通常更有用
https://docs.aws.amazon.com/zh_cn/Route53/latest/DeveloperGuide/dns-failover-complex-configs.html
Amazon Redshift
Amazon Redshift 与各种数据加载和 ETL(提取、转换和加载)工具以及商业智能 (BI) 报告、数据挖掘和分析工具集成。Amazon Redshift 基于行业标准 PostgreSQL,因此,大多数现有 SQL 客户端应用程序仅处理最少量的更改。 Amazon Redshift 通过使用行业标准 PostgreSQL JDBC 和 ODBC 驱动程序与客户端应用程序进行通信。
数据库表的列式存储大大降低了总体磁盘 I/O 要求,它是优化分析查询性能的一个重要因素。按列式方式存储数据库表信息将减少磁盘 I/O 请求数与需从磁盘加载的数据量。
Amazon CloudFront OAI
利用来源访问标识 (OAI) 功能,您可以仅允许通过 CloudFront 访问 Amazon S3 存储桶。 S3的pre-signed URL,配合lifecycle销毁URL。S3和Cloudfront整合使用的OAI
S3 Batch Operations (批量操作)
通过S3批量操作功能,在S3控制台上通过几次鼠标点击就可以实现批量将对象复制到另一个存储桶、设置对象标签或ACL、触发Glacier/Deep Archive对象还原或者是对每个对象触发指定的Lambda函数进行处理。

S3批量操作目前支持标签替换、ACL替换、对象复制、Glacier/Deep Archive数据还原以及触发Lambda函数。通过Lambda函数我们可以自行编码相应的处理逻辑,从而方便地扩展S3批量操作功能。